Improving your app positioning in Google Play using Keyword scorings.
Selecting the app Keywords to maximize its positioning in the Google Play using R.

This is the fourth entry for the ASO series. After reviewing how to retrieve app keyword rankings, and app profile data from the Google Play, and visualizating the app keywords positioning overtime, I will deep into a novel proposal to choose the Keywords with the highest chance to maximize any app positioning in Google Play.
Before getting into the code, I would like to share my assumptions and reasoning behind this application. You may find a holistic approach for this strategy at the end of this article: What is ASO and why it is important.
Introduction and assumptions
In order to proceed with the app search out of a given keyword term, I suppose that Google Play is using some public and private data to feed its algorithm.
As for the public data I refer to information that is public from the the app profile such as app installs , number of app ratings, app score, partial and exact coincidence of that keyword term with the app title, and app description.
There is also additional public data that Google Play might be using such as the app developer name as well as the text written on the app screenshots and app videos added to the app profile, its app pricing options, age reccomendation, and more.
By the private data, I refer to the data not accessible at the app profile on Google Play such as the app reliability data in form of crashes or ANR (app non responding) errors, user app retention, app conversion rates, other behavioural and demographics data of the app users in possession of Google, external links pointing to the app profile in Google play, and more.
In this line, my proposal is to build a Keyword scoring algorithm based on the assumed most-relevant public data which would be the app installs, app ratings, app score, app title, and app description.
This algorimth calculates a score for each of the Keywords being tracked, and propose the Keywords with the highest chances for an app to positioning for.
Scoring ingredients
I define four fields to calculate the scoring for each keyword:
Authority: the authority represents the weight of the apps competing for a certain keyword which is calculated by the number of installs, ratings, and score. The higher the authority of the apps competing for a certain keyword, the lower the chances to positioning for that keyword; hence, the lower its scoring.
Competition: the competition reflects the density of a certain keyword within the title and description of the apps ranking for that keyword. The higher the competition of the apps ranking in Google Play for a given keyword, the lower the chances to positioning for that keyword; hence, the lower its scoring.
Relevance: the relevance refers to how linked is that keyword with the app purpose and user scope. I just work with high relevancy keywords. Therefore this field is dropped since my assumption is that relevance is 100% for the bag of keywords being analyzed.
Traffic: the traffic is an estimation of the volume of searches processed by Google Play for a certain Keyword. The higher the traffic, the higher the value when positioning for that Keyword; hence, the higher its scoring.
Let´s put this into work.
Coding it
The first thing you should do if you have extracted the data from the app profiles, as detailed in the second article of this ASO series, is to wrangle and parse the app installs, ratings and score. I won´t pay further attention to this point but it´s required to continue.
Second step is to leverage the weight of the app title data over the app description (*). As you may guess, it is a clear that keywords present in the title will have a stronger weight for Google Play when ranking them upon a given search. But, how much? After hearing some ASO analysts, I´ve gone for 4 times as much. You may decide otherwise, just change the weight.
(*) The short term app description might also be weighted if available.
library(stringr)
title_weight = 4
# Arranging the text for analysis
for (i in 1:title_weight) {
KW_search$Arranged <- str_c(KW_search$Title, ' ', KW_search$Arranged)
}
With the aim to facilitate the counting of keyword macthes through the weighted text, I suggest you wrangling the input data as follows:
KW_search$Arranged <- str_c(KW_search$Long_desc, ' ', KW_search$Arranged) %>%
str_to_lower() %>%
stri_trans_general('Latin-ASCII') %>%
str_replace_all(regex("\\W+"), " ") %>%
str_squish()As for the matches calculation, I use the suited-to-my-keywords code below. The goal is to remove common prepositions and conjunctions as well as standarize plural and and gender particularities from relevant keywords of the mostly-localized Spanish app profiles I´m analyzing.
KW_search$Exact_match <- str_count(KW_search$Arranged, KW_search$Keyword_search)
for (i in 1:nrow(KW_search)) {
partial_match <- str_squish(KW_search$Keyword_search[i])
partial_match <- str_split(partial_match,' ')[[1]] %>%
str_replace_all('.s$', paste0('(',
str_sub(str_split(partial_match, ' ')[[1]],-2,-2),
'|',
str_sub(str_split(partial_match, ' ')[[1]],-2,-1),
')')) %>%
# Plurals
str_replace_all('mujer\\(e\\|es\\)', 'muje(r|res)') %>%
str_replace_all('mejor\\(e\\|es\\)', 'mejo(r|res)') %>%
str_replace_all('anterior\\(e\\|es\\)', 'anterio(r|res)') %>%
str_replace_all('muscular\\(e\\|es\\)', 'muscula(r|res)') %>%
str_replace_all('militar\\(e\\|es\\)', 'milita(r|res)') %>%
str_replace_all('temporizador\\(e\\|es\\)', 'temporizado(r|res)') %>%
str_replace_all('abdominal\\(e\\|es\\)', 'abdomina(l|les)') %>%
str_replace_all('corporal\\(e\\|es\\)', 'corpora(l|les)') %>%
str_replace_all('facil\\(e\\|es\\)', 'faci(l|les)') %>%
str_replace_all('semanal\\(e\\|es\\)', 'semana(l|les)') %>%
str_replace_all('personal\\(e\\|es\\)', 'persona(l|les)') %>%
str_replace_all('intensidad\\(e\\|es\\)', 'intensida(d|des)') %>%
# Killing prepositions and conjunctions
str_replace_all('^para$', '###') %>%
str_replace_all('^de$', '###') %>%
str_replace_all('^en$', '###') %>%
str_replace_all('^por$', '###') %>%
str_replace_all('^con$', '###') %>%
str_replace_all('^y$', '###') %>%
str_replace_all('^sin$', '###') %>%
# Allow multiple combination of single nouns and adj. for partial matches.
str_c(collapse = '|')
# Partial matches
KW_search$Partial_matches[i] <- str_count(KW_search$Arranged[i], partial_match)
}Once the matches have been calculated, I build a summary of medians for the top10 and top30 ranked apps by matches, installs, ratings and scores.
KW_sum <- KW_search %>%
na.omit() %>%
group_by(Keyword_search) %>%
summarize(T30_med_exact_match = median(Exact_match[Ranking <=30], na.rm = T),
T30_med_partial_match = median(Partial_matches[Ranking <=30], na.rm = T),
T30_med_installs = median(Rev_installs[Ranking <=30], na.rm = T),
T30_med_ratings = median(Rev_ratings[Ranking <=30], na.rm = T),
T30_med_score = median(Rev_score[Ranking <=30], na.rm = T),
T10_med_exact_match = median(Exact_match[Ranking <=10], na.rm = T),
T10_med_partial_match = median(Partial_matches[Ranking <=10], na.rm = T),
T10_med_installs = median(Rev_installs[Ranking <=10], na.rm = T),
T10_med_ratings = median(Rev_ratings[Ranking <=10], na.rm = T),
T10_med_score = median(Rev_score[Ranking <=10], na.rm = T))
KW_sum$Date <- end_dateThen, I compute an normalized adjustment of the competition and authority divided by top10 and top30. I also use an exact match multiplier to positively have into account the apps matching in their title and description the Keyword searched.
#Exact match multiplier
EM_scr <- 4
# Define normalization function
norm <- function(x) {
(x - min(x)) / (max(x) - min(x))
}
# Computing T30 and T10 scores out of normalized values
KW_sum$T30_Competence <- (EM_scr * norm(KW_sum$T30_med_exact_match) + norm(KW_sum$T30_med_partial_match)) / (EM_scr + 1) #Skewed
KW_sum$T30_Authority <- norm(KW_sum$T30_med_score) * norm(KW_sum$T30_med_installs) * norm(KW_sum$T30_med_ratings) #Skewed
KW_sum$T10_Competence <- (EM_scr * norm(KW_sum$T10_med_exact_match) + norm(KW_sum$T10_med_partial_match)) / (EM_scr + 1)
KW_sum$T10_Authority <- norm(KW_sum$T10_med_score) * norm(KW_sum$T10_med_installs) * norm(KW_sum$T10_med_ratings)
# Computing T30 and T10 opportunity scores
KW_sum$T30_OC <- KW_sum$T30_Competence * KW_sum$T30_Authority
KW_sum$T10_OC <- KW_sum$T10_Competence * KW_sum$T10_AuthorityEventually, I create a data frame with the results of the competition and authority opportunity scores, add the search volumes(*) for the Keywords analyzed, and calculate the Keyword full score.
(*) I use the google search web volumes reported by SemRush as a proxy to app searches.
# Table with Opportunity Score calculated out of Competence and Authority
KW_table <- KW_sum[,
c('Keyword_search',
'T30_OC',
'T10_OC',
'Date',
'Search_volume')] %>%
filter (!is.na(Search_volume)) %>%
arrange(desc(Search_volume))
KW_table$Full_score <- round((1- (norm(KW_table$T10_OC) + norm(KW_table$T30_OC))/2) * norm(KW_table$Search_volume),2)
In the last step of this script, I divide the Keywords into two groups: the ones that I´m currently ranking for according to my title and long description, and the ones I´m NOT ranking for but I´m nonetheless tracking.
I then arrange a table showing my worst-scoring ranking Keyword along with the best-scoring non-ranking Keyword from my list. My second worst-scoring ranking Keyword along with the second best-scoring non-ranking Keyword, and so on.
The goal of this exercise is twofold:
To easily detect the Keywords that are not working well for my positioning (commonly due to the competition and authority of other apps), and
To be served with the best Keyword out of the ones tracked to replace the worst-scoring one currently in use.
I´ve also included a threshold on the minimum scoring distance among a pair of exiting and entering Keywords to be shown in my script output.
thr <- 0.05
for (i in 1:length(KW_used$Keyword_search)) {
if ((KW_nonused$Full_score[i] - KW_used$Full_score[i]) > thr) {
KW_used$KW_exchange_proposal[i] <- KW_nonused$Keyword_search[i]
KW_used$KW_proposal_score[i] <- KW_nonused$Full_score[i]
KW_used$KW_exchange_score_diff[i] <- KW_nonused$Full_score[i] - KW_used$Full_score[i]
} else {
KW_used$KW_exchange_proposal[i] <- NA
KW_used$KW_proposal_score[i] <- NA
KW_used$KW_exchange_score_diff[i] <- NA
}
}
KW_used[!is.na(KW_used$KW_exchange_proposal), c('Keyword_search',
'Full_score',
'KW_exchange_proposal',
'KW_proposal_score',
'KW_exchange_score_diff')]Voila!
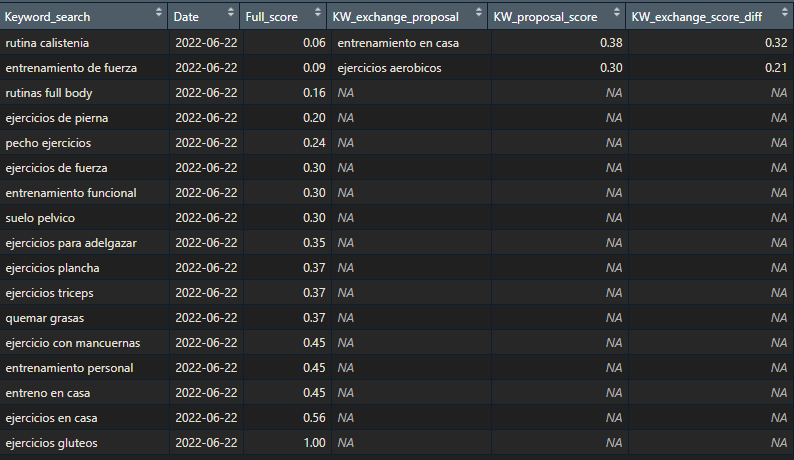
This would be all for today.
If you´d like to know more about how to automate the daily reporting of Keyword tracking chart and Keywords exchange proposals based on their scoring stay tuned since I will write about that in my next ASO article.
Should you have any comment or request, do not hesitate to get in contact with me by email at datadventures@substack.com